
Low level routines for simulation
As regards bots, I use the widespread solution of bounding the Timestep, with the following implementation:
Each bot has its own time BotTime, which is initialized to the GameTime at the start of a round.
Then, at the start of each bot update:
BotTimeStep= min( GameTimen-BotTimen-1, TIMESTEPMAX)
BotTimen= BotTimen-1 + BotTimeStep
BotTimeStep is the timestep value used in all bot thinking/acting code.
TIMESTEPMAX= 100 milliseconds.
Implementing a dynsyst altering variables ( an "in-the-loop" dydnsyst) would then look like:
Impl1:
IdealAnglen= ...;
FinalAnglen= dynsyst( IdealAnglen, FinalAnglen-1);
engine( FinalAnglen);
In this implementation, the dynsyst is a blackbox inserted between the bot AI output and the engine input. If need be, you can in particular run the dynsyst code N times for a given IdealAngle, with the dydnsyst own Timestep being the engine Timestep/N, and the output forwarded to the engine being the dydnsyst output of the last( Nth)dynsyst commputation step.
Or
Impl2:
IdealAnglen= ...;
FinalAnglen= dynsyst( IdealAnglen, EngAnglen-1);
engine( FinalAnglen);
In this second implementation, the engine is in the dynsyst loop, which requires a
good knowledge on how the engine works, especially for stability analysis...so I do not use it.
Implementing a perturbation would look like:
IdealAnglen= ...;
Perturbationn=PertGenerator();
FinalAnglen= IdealAnglen+ Perturbationn;
engine( FinalAnglen);
1.One key point is that the dynsyst is most of the time placed within a closed loop, ie is dependent of the whole game loop. More precisely, this is obviously always the case for an implementation of type "Impl2". This also happens for "Impl1" whenever the IdealAngle computation in the bot AI depends on Engine outputs( usually the relative positions of the viewer and the target).
This makes it trickier to handle than the perturbation model.
This is why I would recommend using a perturbation model instead of an "in-the-loop" dynsyst if possible.
Unfortunately, only an "in-the-loop" dynsyst will be able to simulate the player in term of reaction time ( for detecting and execution), mouse speed and acceleration bounds, etc...
2.the "in-the-loop" dynsyst may unduly alter the behaviour of the game.
For example, with the "Impl2",
if the engine adds a perturbation( like recoil) to the bot input,
the dynsyst will detect an error and compensate for it,
whereas a real player would most probably not be able to do that.
Note: in the recoil example, the only solution I see is to use (EngAngle-EngRecoil) as feedback instead of EngAngle, so that the dynsyst "does not see" the recoil.
3.As regards "in-the-loop" dynsysts, where they are placed in the code may give
seemingly equivalent but actually different results.
For example, assuming the dynsyst is a simple first order filter and
one wants to bound the speed.
One can implement a rate bounder within the dynsyst itself;
the FinalAngle speed will then be bounded in all case.
Or one can "preliminary" bound the speed of IdealAngle as:
IdealAnglen= ...;
BoundedRateIdealAnglen= rateBounder( IdealAnglen, BoundedRateIdealAnglen-1..);
FinalAnglen= dynsyst( BoundedRateIdealAnglen, FinalAnglen-1);
In that case, FinalAngle will only "see" IdealAngle commands as ramp inputs, which will also bound the speed as required, but the response curve will be different on a step change on IdealAngle from the first choice.
Moreover, for Impl2, FinalAngle speed is not bounded when the dynsyst reacts to a perturbation on EngAngle.
4.Dynsysts, and especially 2nd order dynsysts are fairly flexible.
For example, by assigning different parameters, one may simulate the cool-handed player ( damping> 0.7) or the panicked player trying to shoot its enemy stabbing him while "dancing" around him ( damping< 0.3).
But the dynsysts alone feel too deterministic.
Especially in the last situation, introducing noise seems to me to be a better choice.
Randomly varying the dynsyst parameters would bring a bit of a change,
but I would think that fast and big variations, except for a situation change as in the example,
would result in an irrealistic behaviour( but I did not try).
Actually, what we want to simulate, letting aside decision making and control,
should be adressed with two different systems:
1. One system which deals with the player viewed as a sensor.
This relates to a first phase of detection and identification
( probability of detection, detection reaction time), which is not addressed here.
Then it relates to the subsequent phase of evaluating the variables of interest ( inaccuracy of data).
"Estimators" dynsysts are used in that phase.
2. Another system, using data provided by the first for feedback along with AI ouputs for commands, which deals with the player viewed as an actuator.
This relates to the dynamic of mouse move ( muscles are involved,...),
which includes reaction time, inaccuracy, speed, acceleration bounds,...
Still, for sake of simplicity, my design goal was to find a dynsyst that can simulate both.
A problem arises from the fact that azimuth and elevation ( yaw and pitch in Counter-Strike)
should vary consistently.
If one uses a linear dynsyst for yaw and another one with the same parameters for pitch,
both angles will close up to their respective input ( perfect) value at the same time.
Behavior may even still be acceptable if the parameters are different,
or the even if the dynsysts, while still linear, are different.
But if using non linear dynsyst(s), behavior will on the contrary
a priori be not acceptable.
For example, if the dynsysts are bounding the speed of the angles,
one angle may reach its final value markedly earlier than the other.
I have tried 2 solutions.
Solution 1:Angle between vectors
I choosed the key variable to be the angle between the 2 vectors associated with the input (perfect)
angles and the previous ouput angles.
This angle would be input in any dynsyst that would reduce it to zero, and the new
output angles derived from the resulting output. The view vector would then rotate
around the cross-product of the input and previous ouput vectors.
Two cases complicate the code: when the angle comes close to zero,
and -nastier- when it is equal to 180 degrees ( which rotation vector should be used?).
Anyway this solution does not provide what we need.
As an example, a bot looking slightly above the horizon to north
and deciding to look slightly above the horizon to south would move its
view vector in a vertical plane!
Solution 2: Combined variables
Keeping with the idea of dealing with only one variable and one dynsyst,
I choosed a combined error from the yaw and pitch errors:
YawErr= yawInputn- yawOutputn-1;
PitchErr= pitchInputn- pitchOutputn-1;
CombError= sqrt(YawErr2+ PitchErr2);
I used a variation of a first order filter ( N1LB ) which reduces its input to zero ( high pass filter):
UpdatedCombError= dynsyst( CombError).
( Note:A first order works with an input (CombError) that cannot be negative
because the updated output value is always between the input and the previous output.)
Getting updated yaw and pitch errors:
yawErrn= YawErr* UpdatedCombError/ CombError;
pitchErrn= PitchErr* UpdatedCombError/ CombError;
and finally get updated yawn and pitchn as:
yawOutputn =yawInput- yawErrn
pitchOutputn =pitchInput- pitchErrn
Some ideas for extensions...
-Add a second subsequent filtering stage with separate linear filters on yawOutputn
and pitchOutputn
-Add a second preceding filtering stage with separate linear filters before Combination
-Different weights for yaw and pitch
-...
Afterthought: CombError looks like a distance which seems odd
but angles variations are actually mouse moves in the xy plane.
This lead me to a different frame of thinking, and consider simulating view_angles move
by using solutions for path control in the xy plane.
Moreover, a human player does not drive the mouse in the x plane ( say pitch)
with the same arm move than in the y plane ( say yaw).
So yaw and pitch consistent moving may not be that hard a constraint after all.
This is why I currently use two separate N2KN_AS dynsysts for yaw and pitch ( with no acceleration bounds), with the speed estimation process bypassed
when irrelevant (eg: switching targets ).
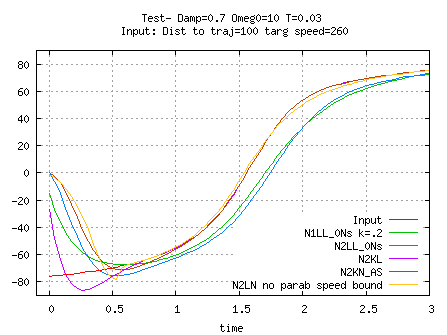
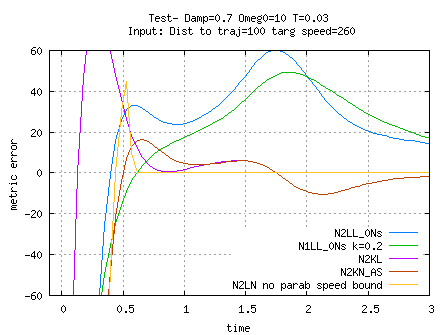
The N2KN_AS dynsyst seems to me to be the best solution, but I finally do not like the idea of destabilizing the dynsyst ( decrease damping down to .3 or .2) to model a nervous player.
Viewing the inability of a human player to point straight to its spot target as an inability
to ever know the exact relationship between a mouse move on the desk and an angle on the screen,
I wound up with the following model:
When aiming, the player systematically makes an error, implemented as a
perturbation offset to the ideal view angle.
This perturbation is constant until the view angle comes close to the ideal one:
at that time, the player evaluates the next mouse move to be performed and makes again an error.
The process is endlessly repeated, and converges as the perturbation is choosen to be
a random coefficient with Mean=0 multiplied by abs( input-ouput).
One should note that adding a proportion of (input-ouput) actually
alters the dynsyst stability, which is here a nice side effect.
Hence a nervous player will have a dynsyst with approximatively the same damping ( >=1.0 probably)
and greater frequency ( faster), but will have a higher proportion for the perturbation.
The perturbation update is triggered by the condition ( working for constant speed targets):
abs((idealn-idealn-1)-(ouputn-ouputn-1))< Epsilon ( to be defined),
and also when the target changes.
The underlying assumptions is that a human player is not 100% a continuous system, constantly evaluating, comparing all variables and thinking, reacting all the time on everything. I would rather compare the player to a multithreaded system, sharing limited resources ( like capacity of thinking/sensing focus)( anything on the Net on that topic?).
I did not go any further in designing this solution but preliminary testing
indicates that it could be my ultimate best one.
Stopping distance
When moving straight and changing bot speed input setting to zero , speed dynamics in game-engines are such that the bot still moves on what I call the stopping distance before actual speed is zero.
This can reasonably, if not exactly, be modelled by first order , possibly non-linear, dynsysts like
N1LL,
N1LL_Ns,
N1LA,
N1LB.
For the models told about hereabove, the speed decays as an exponential on some portion of its drop, or at constant rate ( constant deceleration). It is the case for Half-life ( see "Bot Navigation").
Knowing this stopping distance helps to better control bot move in several cases:
- when it must stops on a point, a line or a plane
- when it must avoid crossing a line or a plane; in that case, a stopping distance check can trigger a safe direction change ( ie early enough in all cases).
- when, in bot navigation, it must know when to switch from its current path segment to the next.
Here are several models for game-engine speed dynamics.
is the bot speed input to the engine.
The position follows a simple integration scheme as = + T* or = + T*
is the speed when is set to zero.
Linear model( N1LL): = + A* ( - ) then stopping distance is **/A.
Linear model( N1LL_Ns): = + A* ( - ) then stopping distance is **(1-A)/A.
Constant deceleration model with N= (int)( / Decel*): = - N** Decel and = + T* then stopping distance is N*( - 0.5* Decel*)- 0.5* Decel * (N)2
Constant deceleration model: = - T* Decel and = + T* then stopping distance is
N*( - 0.5* Decel*)- 0.5* Decel * (N)2+ .
Calculating speed and position for speed decay behaviour combining a mix of these models can be done; formulas for a first order linear filter giving the integral of the output on a step input are provided in N1LL and
N1LL_Ns.
Doing the same for constant deceleration and using the formulas piece-wise gives the answer, as can be applied to HalfLife:
.
Half-Life model: for initial speed above \"stopspeed\" cvar, speed decays exponentially, then in all cases the speed drop is linear; code is provided in \"Bot Navigation\".
A more practical solution can be to use a approximate model ( the linear one is the simplest), providing it is conservative, ie approximate stopping distance > true stopping distance.